
A tutorial on some of the Basics needed to use the Apache Commons Pipeline workflow framework. The target audience for this document consists of developers who will need to assemble existing stages or write their own stages. The pipeline provides a Java class library intended to make it easy to use and reuse stages as modular processing blocks.
Stages in a pipeline represent the logical the steps needed to process data. Each represents a single high level processing concept such as finding files, reading a file format, computing a product from the data, or writing data to a database. The primary advantage of using the Pipeline framework and building the processing steps into stages is the reusablility of the stages in other pipelines.
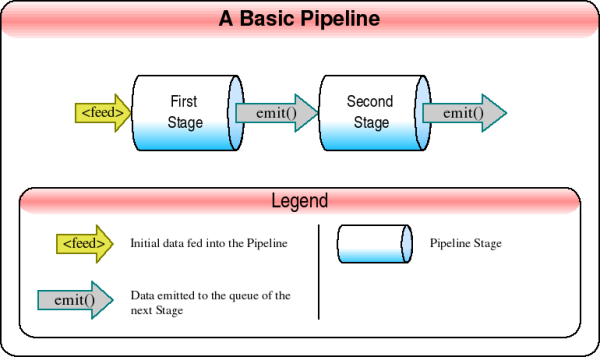
A Pipeline
is built up from stages which can pass data on
to subsequent stages. The arrows above that are labelled
"EMIT"
show the data output of one stage being
passed to the next stage. At the code level, there is an
emit() method that sends data to the next stage.
The data flow starts at the left, where there is an arrow
labelled "FEED"
. The FEED starts off the
pipeline and is usually set up by a configuration file,
discussed below. The stages themselves do not care if the
incoming data are from a feed or the emit() of a
previous stage.
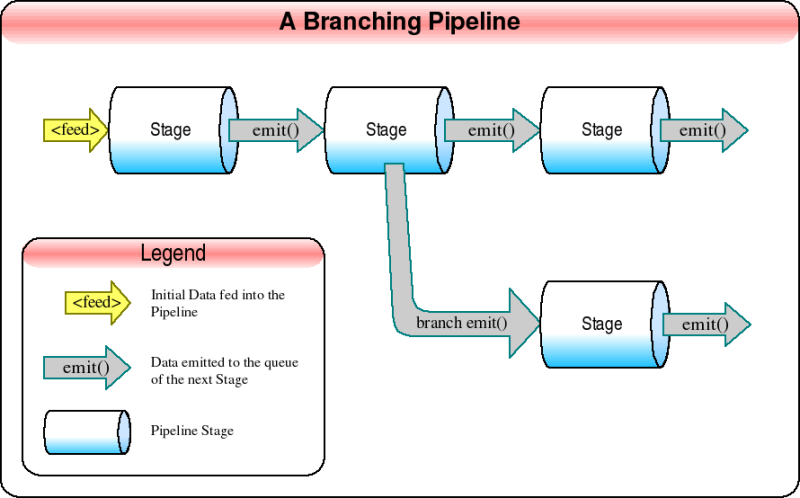
Pipelines may also branch to send the same or different data along
different processing routes.
There are two methods for configuring the Pipeline, both based on XML control files. The simpler method uses Digester , end users of a pipeline may be able to modify this for themselves. The Spring framework has also been used to configure the Pipeline, but it is both more complex and more powerful, as it's structure more closely models Java programming objects. The stages are ordered by these XML configuration files, and stage specific parameters are set up by these files. These control files also allow global parameters visible to all stages in the form of Environment parameters. This configuration approach allows alot of control over the pipeline layout and behavior, all without recompiling the Java code.
This tutorial will introduce the Digester route to configuring pipelines since that is the simpler method.
A standard stage has a queue to buffer the incoming data objects. The queueing is an aid to efficiency when some stages have different rates of throughput than other stages or irregular processing rates, especially those relying on network connections or near-line media for their data. This queue is not an actual part of the stage itself but is managed by a stage driver , which feeds the objects to the stage as it is ready for them. The stage passes a data object on to the next stage, where it may wait in a queue (in the order received) until the next stage is ready to process it. Typically each stage runs in its own processing thread, however, for some applications you can configure the pipeline to run objects one at a time through all the stages in a single thread, that is, the next object is not started until the previous has finished all the stages.
Stages are derived from the abstract class
org.apache.commons.pipeline.stage.BaseStage
.
There are a number of ready to use existing stages to meet various
processing needs. You may also create custom stages by extending the
BaseStage or one of the other existing stages.
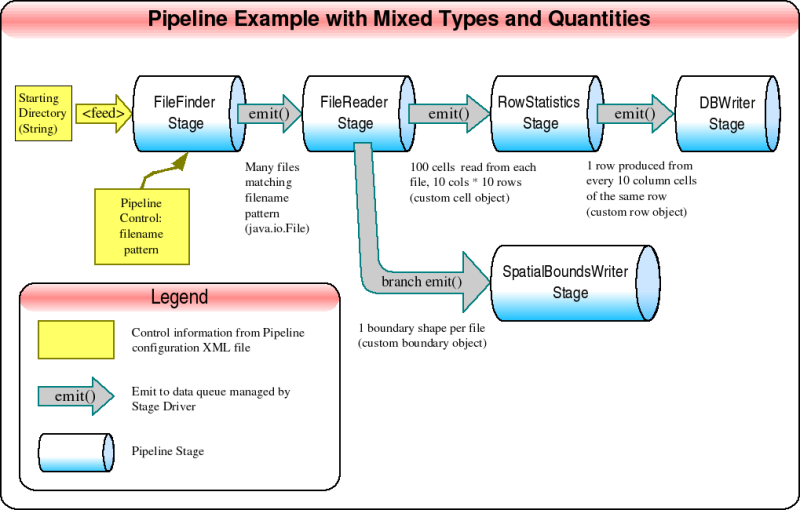
An example showing mixed types and quantities, see notes below
figure.
There is a Java interface called the StageDriver which controls the feeding of data into Stages, and communication between stages and the pipeline containing them. The stage lifecycle and interactions between stages are therefore very dependent on the direction provided by these stage drivers. These StageDriver factories implement the StageDriverFactory interface. During pipeline setup, the StageDrivers are provided by factory classes that produce a specific type of StageDriver. Each stage will have its own instance of a StageDriver, and different stages within a pipeline may use different types of StageDrivers, although it is common for all stages in a pipeline to use the same type of StageDriver (all sharing the same StageDriverFactory implementation).
Some common stage drivers are:
DedicatedThreadStageDriver
|
Spawns a single thread to process a stage. Provided by
DedicatedThreadStageDriverFactory() |
SynchronousStageDriver
|
This is a non-threaded StageDriver. Provided by
SynchronousStageDriverFactory() |
ThreadPoolStageDriver
|
Uses a pool of threads to process objects from an input
queue. Provided by
ThreadPoolStageDriverFactory() |
This tutorial will cover the
DedicatedThreadStageDriver since that is a good
general purpose driver. You may at some point wish to write your
own StageDriver implementation, but that is an advanced topic
not covered here.
If you need to write your own stage, this section gives an overview on some methods you will need to know about in order to meet the Stage Interface.
Stage
itself is an interface defined in org.apache.commons.pipeline.Stage and it must have the following methods:
Stage
Interface Methods
|
|
init(StageContext)
|
Associate the stage with the environment. Run once in lifecycle. |
preprocess()
|
Do any necessary setup. Run once in lifecycle. |
process(Object)
|
Process an object & emit results to next stage. Run N times, once for each object fed in. |
postprocess()
|
Handle aggregated data, etc. Run once in lifecycle. |
release()
|
Clean up any resources being held by stage. Run once in lifecycle. |
An abstract class is available called
org.apache.commons.pipeline.BaseStage
from which many other
stages are derived. You can extend this class or one of the other stages built
upon BaseStage. This provides no-op implementations of the Stage interface
methods. You can then override these methods as needed when you extend one of
these classes. For simple processing you may not need to override
init(StageContext), postprocess(), nor
release(). You will almost always be providing your own
process(Object) method however. From a software design perspective,
think of Inversion of Control
, since instead of writing a custom main
program to call standard subroutines, you are writing custom subroutines to be
called by a standard main program.
BaseStage
provides a method called emit(Object obj), and
emit(String branch, Object obj) for branching, which sends objects
on to the next Stage. Thus it is normal for emit() to be called
near the end of process(). A terminal stage
simply doesn't
call emit(), so no objects are passed on. It is also very easy to
change a stage so it is not a terminal stage by adding an emit() to
the code. Note that it is harmless for a stage to emit an object when there is
no subsequent stage to use it; the emitted object just goes unused. Sometimes
the emit() method is called by postprocess() in
addition to or instead of by process(). When processing involves
buffering, or summarizing of incoming and outgoing objects, then the
process() method normally stores information from incoming objects,
and postprocess() finishes up the work and emits a new object.
When a pipeline is assembled and run, each stage is normally run in its own
thread (with all threads of a pipeline being owned by the same JVM instance).
This multithreaded approach should give a processing advantage on a
multiprocessor system. For a given stage, the various Stage methods are run in
order: init(), preprocess(), process(),
postprocess() and release(). However, between stages,
the order that the various methods begin and complete is not deterministic. In
other words, in a pipeline with multiple stages, you can't count on any
particular stage's preprocess() methods beginning or completing
before or after that method in another stage. If you have dependencies between
stages, see the discussion on Events and Listeners in the Communication
between Stages
section below.
The order of stages in a pipeline is determined by the pipeline configuration
file. With Digester, this is an XML file which lists the stages to be used, plus
initialization parameters. As each stage is added to the pipeline, its
init() method is executed. After all the stages of the pipeline
have been loaded into place the pipeline is set to begin running. The
preprocess() method is called for the various stages. When using
the DedicatedThreadStageDriver each stage begins running in its own
thread, and the preprocess() methods are run asynchronously.
When the first stage of a pipeline is done with its preprocess()
method, it will begin running process() on objects being fed in by
its associated stage driver. As the first stage is done processesing data
objects, they will be emitted to the next stage. If the next stage is not
finished with its own preprocess() method, the passed data objects
will be queued by the second stage's stage driver. When all the initial objects
have been processed by the first stage's process() method, then it
will then call the postprocess() method. When the
postprocess() method is complete, a STOP_REQUESTED signal is sent
to the next stage to indicate that no more objects will be coming down the
pipeline. The next stage will then finish processing the objects in its queue
and then call its own postprocess() method. This sequence of
finishing out the queue and postprocessing will propagate down the pipeline.
Each stage may begin running its release() method after finishing
the postprocess(). init() and release()
should not have any dependencies outside their stage.
Each stage can be configured to stop or continue should a fault occur during
processing. Stages can throw a StageException during
preprocess(), process(), or
postprocess(). If configured to continue, the stage will begin
processing the next object. If configured to stop on faults, the stage will end
processing, and any subsequent process() or
postprocess() methods will not
be called. The
release() method will always be called, as it resides in the
finally block of a try-catch construct around the
stage processing.
There are two primary mechanisms for Stages to communicate with each other. In
keeping with the dataflow and "Pipeline" analogy, these both send
information "downstream" to subsequent stages.
emit() to
(queue of) next Stage
-
sequential passage of data objects. These objects are often implemented as Java
Beans, and are sometimes referred to as "data beans".
As an example of the Event and Listener, suppose you have one stage reading from
a database table, and a later stage will be writing data to another database.
The table reader stage should pass table layout information to the table writer
stage so that the writer can create a table with the proper fields in the event
the destination table does not already exist. The
TableReader.preprocess() method will raise an event that carries
with it the table layout data. The preprocess() method of the
following TableWriter stage is set up to listen for the table event, and will
wait until that event happens before proceeding. In this way the TableWriter
will not process objects until the destination table is ready.
Now it's time to present the Pipeline configuration file , which is writtten in XML when using Digester.
Here is an example showing the basic structure. This pipeline has three stages and an environment constant defined. A summary of the elements shown follows the sample code.
<?xml version="1.0" encoding="UTF-8"?>
<!--
Document : configMyPipeline.xml
Description: An example Pipeline configuration file
-->
<pipeline>
<driverFactory className="org.apache.commons.pipeline.driver.DedicatedThreadStageDriverFactory"
id="df0"/>
<!-- The <env> element can be used to add global environment variable values to the pipeline.
In this instance almost all of the stages need a key to tell them what type of data
to process.
-->
<env>
<value key="dataType">STLD</value>
</env>
<!-- The initial stage traverses a directory so that it can feed the filenames of
the files to be processed to the subsequent stages.
The directory path to be traversed is in the feed block following this stage.
The filePattern in the stage block is the pattern to look for within that directory.
-->
<stage className="org.apache.commons.pipeline.stage.FileFinderStage"
driverFactoryId="df0"
filePattern="SALES\.(ASWK|ST(GD|GL|LD))\.N.?\.D\d{5}"/>
<feed>
<value>/mnt/data2/gdsg/sst/npr</value>
</feed>
<stage className="gov.noaa.eds.example.Stage2"
driverFactoryId="df0" />
<!-- Write the data from the SstFileReader stage into the Rich Inventory database. -->
<stage className="gov.noaa.eds.sst2ri.SstWriterRI"
driverFactoryId="df0"/>
</pipeline> |
Here is a summary explanation of items in the above example
<?xml version="1.0" encoding="UTF-8"?> |
<!-- Standard XML comment --> |
<pipeline>...</pipeline> |
<pipeline>
and surrounds the rest of the configuration.
<driverFactory className="org.apache.commons.pipeline.driver.DedicatedThreadStageDriverFactory" id="df0"/> |
<env> <value key="dataType">STLD</value> </env> |
<stage className="org.apache.commons.pipeline.stage.FileFinderStage" driverFactoryId="df0" filePattern="SALES\.(ASWK|ST(GD|GL|LD))\.N.?\.D\d{5}"/> |
<feed> <value>/mnt/data2/gdsg/sst/npr</value> </feed> |
<feed>
values. In this example, the FileFinderStage expects at least one starting directory from which to get files. Note that the <feed> must come after the first stage in the pipeline in the configuration file. Stages are created as they are encountered in the configuration file, and without any stage defined first, feed values will be discarded.
The second example shows a minimal pipeline with two stages. The first stage is
a FileFinderStage, which reads in file names from the starting directory
"/data/sample" and passes on any starting with
"HelloWorld". The second stage is a LogStage, which is commonly used
during debugging. LogStage writes it's input to a log file using the passed in
object's toString method and then passes on what it receives to the
next stage, making it easy to drop between any two stages for debugging purposes
without changing the objects passed between them.
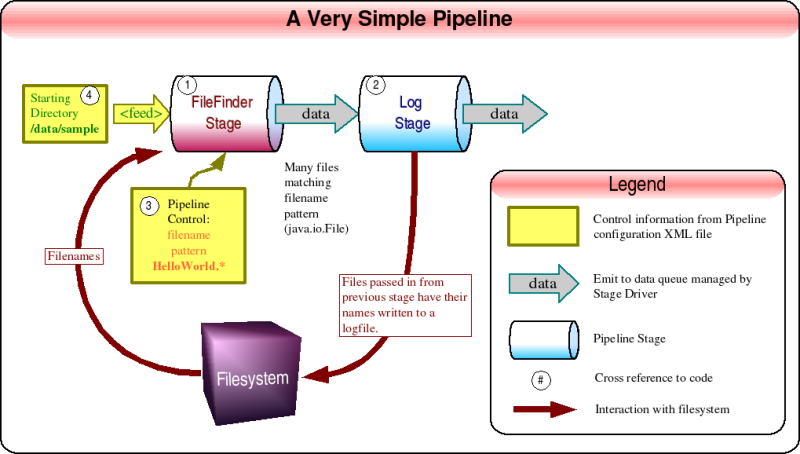
The configuration file corresponding the the image above has some colored text
to make it easier to match the elements to the objects in the image.
<?xml version="1.0" encoding="UTF-8"?> <!-- Document : configSimplePipeline.xml Description: A sample configuration file for a very simple pipeline --> <pipeline> <driverFactory className="org.apache.commons.pipeline.driver.DedicatedThreadStageDriverFactory" id="driverFactory"/> <!-- ((1)) The first stage recursively searches the directory given in the feed statement. The filePattern given will match any files beginning with "HelloWorld". --> <stage className="org.apache.commons.pipeline.stage.FileFinderStage" driverFactoryId="driverFactory" filePattern="HelloWorld.*"/><!-- ((3)) --> <!-- Starting directory for the first stage. --> <feed> <value>/data/sample</value> <!-- ((4)) --> </feed> <!-- ((2)) Report the files found. --> <stage className="org.apache.commons.pipeline.stage.LogStage" driverFactoryId="driverFactory" /> </pipeline> |
One driver factory serves both stages. The driver factory ID is
"driverFactory", and this value is used by the driverFactoryId in both
stages.
In theory a pipeline could consist of just one stage, but this degenerate case
is not much different from a plain program except that it can be easily expanded
with additional stages.
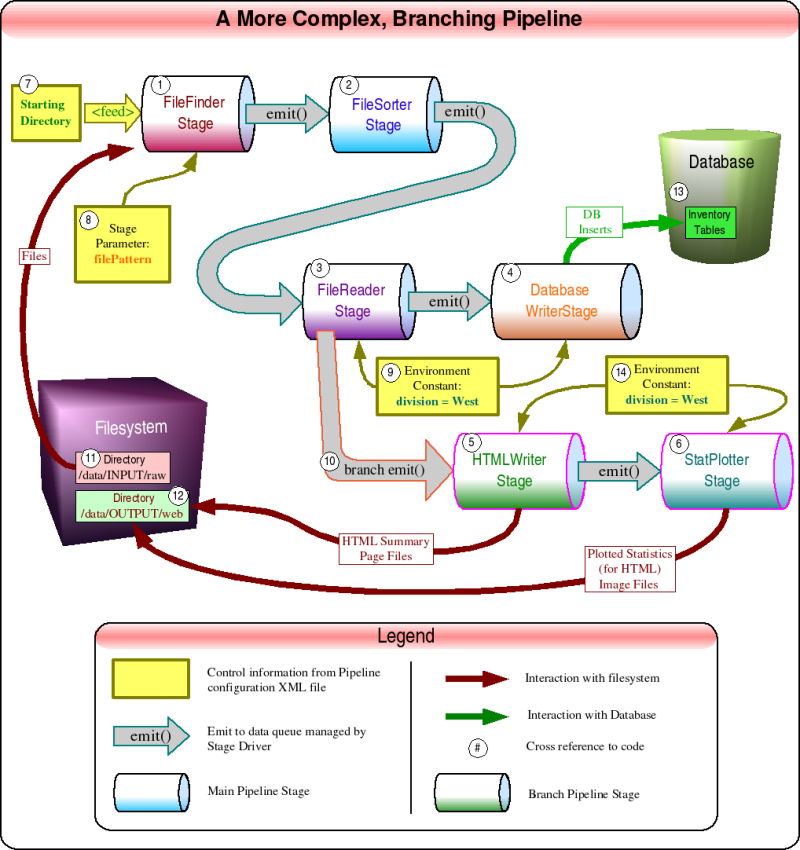
A color coded configuration file:
<?xml version="1.0" encoding="UTF-8"?> <!-- Document : branchingPipeline.xml Description: Configuration file for a pipeline that takes user provided files as input, and from that both generates HTML files and puts data into a database. --> <pipeline> <driverFactory className="org.apache.commons.pipeline.driver.DedicatedThreadStageDriverFactory" id="df0"/> <driverFactory className="org.apache.commons.pipeline.driver.DedicatedThreadStageDriverFactory" id="df1"> <property propName="queueFactory" className="org.apache.commons.pipeline.util.BlockingQueueFactory$ArrayBlockingQueueFactory" capacity="4" fair="false"/> </driverFactory> <!-- The <env> element can be used to add global environment variable values to the pipeline. In this instance almost all of the stages need a key to tell them what type of data to process. --> <env> <value key="division">West</value> <!-- ((9)) --> </env> <!-- ((1)) The initial stage traverses a directory so that it can feed the filenames of of the files to be processed to the subsequent stages. The directory path to be traversed is in the feed block at the end of this file. The filePattern in the stage block is the pattern to look for within that directory. --> <stage className="org.apache.commons.pipeline.stage.FileFinderStage" driverFactoryId="df0" filePattern="SALES\.(ASWK|ST(GD|GL|LD))\.N.?\.D\d{5}"/><!-- ((8)) --><feed> <value>/data/INPUT/raw</value> <!-- ((7)), ((11)) --> </feed> <!-- ((2)) This stage is going to select a subset of the files from the previous stage and orders them for time sequential processing using the date embedded in the last several characters of the file name. The filesToProcess is the number of files to emit to the next stage, before terminating processing. Zero (0) has the special meaning that ALL available files should be processed. --> <stage className="com.demo.pipeline.stages.FileSorterStage" driverFactoryId="df1" filesToProcess="0"/> <!-- ((3)) Read the files and create the objects to be passed to stage that writes to the database and to the stage that writes the data to HTML files. WARNING: The value for htmlPipelineKey in the stage declaration here must exactly match the branch pipeline key further down in this file. --> <stage className="com.demo.pipeline.stages.FileReaderStage" driverFactoryId="df1" htmlPipelineKey="sales2html"/> <!-- ((4)) Write the data from the FileReaderStage stage into the database. --> <stage className="com.demo.pipeline.stages.DatabaseWriterStage" driverFactoryId="df1"> <datasource user="test" password="abc123" type="oracle" host="brain.demo.com" port="1521" database="SALES" /> <database-proxy className="gov.noaa.gdsg.sql.oracle.OracleDatabaseProxy" /> <tablePath path="summary.inventory" /> <!-- ((13)) --> </stage> <!-- Write the data from the FileReaderStage stage to HTML files. The outputFilePath is the path to which we will be writing our summary HTML files. WARNING: The value for the branch pipeline key declaration here must exactly match the htmlPipelineKey in the FileReaderStage stage in this file. --> <branch> <pipeline key="sales2html"> <!-- ((10)) --><env> <value key="division">West</value> <!-- ((14)) --> </env> <driverFactory className="org.apache.commons.pipeline.driver.DedicatedThreadStageDriverFactory" id="df2"> <property propName="queueFactory" className="org.apache.commons.pipeline.util.BlockingQueueFactory$ArrayBlockingQueueFactory" capacity="4" fair="false"/> </driverFactory> <!-- ((5)) HTMLWriterStage --> <stage className="com.demo.pipeline.stages.HTMLWriterStage" driverFactoryId="df2" outputFilePath="/data/OUTPUT/web"/> <!-- ((12)) --> <!-- ((6)) StatPlotterStage --> <stage className="com.demo.pipeline.stages.StatPlotterStage" driverFactoryId="df2" outputFilePath="/data/OUTPUT/web"/> <!-- ((12)) --></pipeline> </branch> </pipeline> |
Notes: The "division" configured to "West " in this example in the <env> definition is set in two places. It should be set to the same value in both the main pipeline and the branch pipeline. This is because branches don't share the same environment constants.
The driverFactories "df1" and "df2" override the default queueFactory by specifying the ArrayBlockingQueueFactory . They do this in order to limit the queue sizes of the stages that use df1 or df2, setting a capacity of 4 objects. This is often done to limit the resources used by the pipeline, and may be necessary if an unbounded queue is using all of the available java memory or exceeds the number of open filehandles allowed. The queue size cannot be changed after the queue is created. The fair attribute can be set to "false", since just one thread is accessing the queue. If fair = "true" then there is additional overhead to make sure all threads that access the queue are processed in order (requests are FIFO).
More should be added to this page:
Links to other pipeline resources
Several diagrams and descriptions were drawn from powerpoint presentations by Bill and Kris as well as from the Pipeline code comments.