1 Statistics
1.2 Descriptive statistics
The stat package includes a framework and default implementations for
the following Descriptive statistics:
- arithmetic and geometric means
- variance and standard deviation
- sum, product, log sum, sum of squared values
- minimum, maximum, median, and percentiles
- skewness and kurtosis
- first, second, third and fourth moments
With the exception of percentiles and the median, all of these
statistics can be computed without maintaining the full list of input
data values in memory. The stat package provides interfaces and
implementations that do not require value storage as well as
implementations that operate on arrays of stored values.
The top level interface is
UnivariateStatistic.
This interface, implemented by all statistics, consists of
evaluate() methods that take double[] arrays as arguments
and return the value of the statistic. This interface is extended by
StorelessUnivariateStatistic, which adds increment(),
getResult() and associated methods to support
"storageless" implementations that maintain counters, sums or other
state information as values are added using the increment()
method.
Abstract implementations of the top level interfaces are provided in
AbstractUnivariateStatistic and
AbstractStorelessUnivariateStatistic respectively.
Each statistic is implemented as a separate class, in one of the
subpackages (moment, rank, summary) and each extends one of the abstract
classes above (depending on whether or not value storage is required to
compute the statistic). There are several ways to instantiate and use statistics.
Statistics can be instantiated and used directly, but it is generally more convenient
(and efficient) to access them using the provided aggregates,
DescriptiveStatistics and
SummaryStatistics.
DescriptiveStatistics maintains the input data in memory
and has the capability of producing "rolling" statistics computed from a
"window" consisting of the most recently added values.
SummaryStatistics does not store the input data values
in memory, so the statistics included in this aggregate are limited to those
that can be computed in one pass through the data without access to
the full array of values.
| Aggregate |
Statistics Included |
Values stored? |
"Rolling" capability? |
|
DescriptiveStatistics |
min, max, mean, geometric mean, n,
sum, sum of squares, standard deviation, variance, percentiles, skewness,
kurtosis, median |
Yes |
Yes |
|
SummaryStatistics |
min, max, mean, geometric mean, n,
sum, sum of squares, standard deviation, variance |
No |
No |
SummaryStatistics can be aggregated using
AggregateSummaryStatistics. This class can be used to concurrently
gather statistics for multiple datasets as well as for a combined sample
including all of the data.
MultivariateSummaryStatistics is similar to
SummaryStatistics but handles n-tuple values instead of
scalar values. It can also compute the full covariance matrix for the
input data.
Neither DescriptiveStatistics nor SummaryStatistics
is thread-safe.
SynchronizedDescriptiveStatistics and
SynchronizedSummaryStatistics, respectively, provide thread-safe
versions for applications that require concurrent access to statistical
aggregates by multiple threads.
SynchronizedMultivariateSummaryStatistics provides thread-safe
MultivariateSummaryStatistics.
There is also a utility class,
StatUtils, that provides static methods for computing statistics
directly from double[] arrays.
Here are some examples showing how to compute Descriptive statistics.
- Compute summary statistics for a list of double values
- Using the
DescriptiveStatistics aggregate
(values are stored in memory):
// Get a DescriptiveStatistics instance
DescriptiveStatistics stats = new DescriptiveStatistics();
// Add the data from the array
for( int i = 0; i < inputArray.length; i++) {
stats.addValue(inputArray[i]);
}
// Compute some statistics
double mean = stats.getMean();
double std = stats.getStandardDeviation();
double median = stats.getPercentile(50);
- Using the
SummaryStatistics aggregate (values are
not stored in memory):
// Get a SummaryStatistics instance
SummaryStatistics stats = new SummaryStatistics();
// Read data from an input stream,
// adding values and updating sums, counters, etc.
while (line != null) {
line = in.readLine();
stats.addValue(Double.parseDouble(line.trim()));
}
in.close();
// Compute the statistics
double mean = stats.getMean();
double std = stats.getStandardDeviation();
//double median = stats.getMedian(); <-- NOT AVAILABLE
- Using the
StatUtils utility class:
// Compute statistics directly from the array
// assume values is a double[] array
double mean = StatUtils.mean(values);
double std = FastMath.sqrt(StatUtils.variance(values));
double median = StatUtils.percentile(values, 50);
// Compute the mean of the first three values in the array
mean = StatUtils.mean(values, 0, 3);
- Maintain a "rolling mean" of the most recent 100 values from
an input stream
- Use a
DescriptiveStatistics instance with
window size set to 100
// Create a DescriptiveStatistics instance and set the window size to 100
DescriptiveStatistics stats = new DescriptiveStatistics();
stats.setWindowSize(100);
// Read data from an input stream,
// displaying the mean of the most recent 100 observations
// after every 100 observations
long nLines = 0;
while (line != null) {
line = in.readLine();
nLines++;
stats.addValue(Double.parseDouble(line.trim()));
if (nLines == 100) {
nLines = 0;
System.out.println(stats.getMean());
}
}
in.close();
- Compute statistics in a thread-safe manner
- Use a
SynchronizedDescriptiveStatistics instance
// Create a SynchronizedDescriptiveStatistics instance and
// use as any other DescriptiveStatistics instance
DescriptiveStatistics stats = new SynchronizedDescriptiveStatistics();
- Compute statistics for multiple samples and overall statistics concurrently
- There are two ways to do this using
AggregateSummaryStatistics.
The first is to use an AggregateSummaryStatistics instance
to accumulate overall statistics contributed by SummaryStatistics
instances created using
AggregateSummaryStatistics.createContributingStatistics():
// Create a AggregateSummaryStatistics instance to accumulate the overall statistics
// and AggregatingSummaryStatistics for the subsamples
AggregateSummaryStatistics aggregate = new AggregateSummaryStatistics();
SummaryStatistics setOneStats = aggregate.createContributingStatistics();
SummaryStatistics setTwoStats = aggregate.createContributingStatistics();
// Add values to the subsample aggregates
setOneStats.addValue(2);
setOneStats.addValue(3);
setTwoStats.addValue(2);
setTwoStats.addValue(4);
...
// Full sample data is reported by the aggregate
double totalSampleSum = aggregate.getSum();
The above approach has the disadvantages that the addValue calls must be synchronized on the
SummaryStatistics instance maintained by the aggregate and each value addition updates the
aggregate as well as the subsample. For applications that can wait to do the aggregation until all values
have been added, a static
aggregate method is available, as shown in the following example.
This method should be used when aggregation needs to be done across threads.
// Create SummaryStatistics instances for the subsample data
SummaryStatistics setOneStats = new SummaryStatistics();
SummaryStatistics setTwoStats = new SummaryStatistics();
// Add values to the subsample SummaryStatistics instances
setOneStats.addValue(2);
setOneStats.addValue(3);
setTwoStats.addValue(2);
setTwoStats.addValue(4);
...
// Aggregate the subsample statistics
Collection<SummaryStatistics> aggregate = new ArrayList<SummaryStatistics>();
aggregate.add(setOneStats);
aggregate.add(setTwoStats);
StatisticalSummary aggregatedStats = AggregateSummaryStatistics.aggregate(aggregate);
// Full sample data is reported by aggregatedStats
double totalSampleSum = aggregatedStats.getSum();
1.3 Frequency distributions
Frequency
provides a simple interface for maintaining counts and percentages of discrete
values.
Strings, integers, longs and chars are all supported as value types,
as well as instances of any class that implements Comparable.
The ordering of values used in computing cumulative frequencies is by
default the natural ordering, but this can be overridden by supplying a
Comparator to the constructor. Adding values that are not
comparable to those that have already been added results in an
IllegalArgumentException.
Here are some examples.
- Compute a frequency distribution based on integer values
- Mixing integers, longs, Integers and Longs:
Frequency f = new Frequency();
f.addValue(1);
f.addValue(new Integer(1));
f.addValue(new Long(1));
f.addValue(2);
f.addValue(new Integer(-1));
System.out.prinltn(f.getCount(1)); // displays 3
System.out.println(f.getCumPct(0)); // displays 0.2
System.out.println(f.getPct(new Integer(1))); // displays 0.6
System.out.println(f.getCumPct(-2)); // displays 0
System.out.println(f.getCumPct(10)); // displays 1
- Count string frequencies
- Using case-sensitive comparison, alpha sort order (natural comparator):
Frequency f = new Frequency();
f.addValue("one");
f.addValue("One");
f.addValue("oNe");
f.addValue("Z");
System.out.println(f.getCount("one")); // displays 1
System.out.println(f.getCumPct("Z")); // displays 0.5
System.out.println(f.getCumPct("Ot")); // displays 0.25
- Using case-insensitive comparator:
Frequency f = new Frequency(String.CASE_INSENSITIVE_ORDER);
f.addValue("one");
f.addValue("One");
f.addValue("oNe");
f.addValue("Z");
System.out.println(f.getCount("one")); // displays 3
System.out.println(f.getCumPct("z")); // displays 1
1.4 Simple regression
SimpleRegression provides ordinary least squares regression with
one independent variable estimating the linear model:
y = intercept + slope * x
or
y = slope * x
Standard errors for intercept and slope are
available as well as ANOVA, r-square and Pearson's r statistics.
Observations (x,y pairs) can be added to the model one at a time or they
can be provided in a 2-dimensional array. The observations are not stored
in memory, so there is no limit to the number of observations that can be
added to the model.
Usage Notes:
- When there are fewer than two observations in the model, or when
there is no variation in the x values (i.e. all x values are the same)
all statistics return
NaN. At least two observations with
different x coordinates are required to estimate a bivariate regression
model.
- getters for the statistics always compute values based on the current
set of observations -- i.e., you can get statistics, then add more data
and get updated statistics without using a new instance. There is no
"compute" method that updates all statistics. Each of the getters performs
the necessary computations to return the requested statistic.
- The intercept term may be suppressed by passing
false to the
SimpleRegression(boolean) constructor. When the hasIntercept
property is false, the model is estimated without a constant term and
getIntercept() returns 0.
Implementation Notes:
- As observations are added to the model, the sum of x values, y values,
cross products (x times y), and squared deviations of x and y from their
respective means are updated using updating formulas defined in
"Algorithms for Computing the Sample Variance: Analysis and
Recommendations", Chan, T.F., Golub, G.H., and LeVeque, R.J.
1983, American Statistician, vol. 37, pp. 242-247, referenced in
Weisberg, S. "Applied Linear Regression". 2nd Ed. 1985. All regression
statistics are computed from these sums.
- Inference statistics (confidence intervals, parameter significance levels)
are based on on the assumption that the observations included in the model are
drawn from a
Bivariate Normal Distribution
Here are some examples.
- Estimate a model based on observations added one at a time
- Instantiate a regression instance and add data points
regression = new SimpleRegression();
regression.addData(1d, 2d);
// At this point, with only one observation,
// all regression statistics will return NaN
regression.addData(3d, 3d);
// With only two observations,
// slope and intercept can be computed
// but inference statistics will return NaN
regression.addData(3d, 3d);
// Now all statistics are defined.
- Compute some statistics based on observations added so far
System.out.println(regression.getIntercept());
// displays intercept of regression line
System.out.println(regression.getSlope());
// displays slope of regression line
System.out.println(regression.getSlopeStdErr());
// displays slope standard error
- Use the regression model to predict the y value for a new x value
System.out.println(regression.predict(1.5d)
// displays predicted y value for x = 1.5
More data points can be added and subsequent getXxx calls will incorporate
additional data in statistics.
- Estimate a model from a double[][] array of data points
- Instantiate a regression object and load dataset
double[][] data = { { 1, 3 }, {2, 5 }, {3, 7 }, {4, 14 }, {5, 11 }};
SimpleRegression regression = new SimpleRegression();
regression.addData(data);
- Estimate regression model based on data
System.out.println(regression.getIntercept());
// displays intercept of regression line
System.out.println(regression.getSlope());
// displays slope of regression line
System.out.println(regression.getSlopeStdErr());
// displays slope standard error
More data points -- even another double[][] array -- can be added and subsequent
getXxx calls will incorporate additional data in statistics.
- Estimate a model from a double[][] array of data points, excluding the intercept
- Instantiate a regression object and load dataset
double[][] data = { { 1, 3 }, {2, 5 }, {3, 7 }, {4, 14 }, {5, 11 }};
SimpleRegression regression = new SimpleRegression(false);
//the argument, false, tells the class not to include a constant
regression.addData(data);
- Estimate regression model based on data
System.out.println(regression.getIntercept());
// displays intercept of regression line, since we have constrained the constant, 0.0 is returned
System.out.println(regression.getSlope());
// displays slope of regression line
System.out.println(regression.getSlopeStdErr());
// displays slope standard error
System.out.println(regression.getInterceptStdErr() );
// will return Double.NaN, since we constrained the parameter to zero
Caution must be exercised when interpreting the slope when no constant is being estimated. The slope
may be biased.
1.5 Multiple linear regression
OLSMultipleLinearRegression and
GLSMultipleLinearRegression provide least squares regression to fit the linear model:
Y=X*b+u
where Y is an n-vector regressand, X is a [n,k] matrix whose k columns are called
regressors, b is k-vector of regression parameters and u is an n-vector
of error terms or residuals.
OLSMultipleLinearRegression provides Ordinary Least Squares Regression, and
GLSMultipleLinearRegression implements Generalized Least Squares. See the javadoc for these
classes for details on the algorithms and formulas used.
Data for OLS models can be loaded in a single double[] array, consisting of concatenated rows of data, each containing
the regressand (Y) value, followed by regressor values; or using a double[][] array with rows corresponding to
observations. GLS models also require a double[][] array representing the covariance matrix of the error terms. See
AbstractMultipleLinearRegression#newSampleData(double[],int,int),
OLSMultipleLinearRegression#newSampleData(double[], double[][]) and
GLSMultipleLinearRegression#newSampleData(double[],double[][],double[][]) for details.
Usage Notes:
- Data are validated when invoking any of the newSample, newX, newY or newCovariance methods and
IllegalArgumentException is thrown when input data arrays do not have matching dimensions
or do not contain sufficient data to estimate the model.
- By default, regression models are estimated with intercept terms. In the notation above, this implies that the
X matrix contains an initial row identically equal to 1. X data supplied to the newX or newSample methods should not
include this column - the data loading methods will create it automatically. To estimate a model without an intercept
term, set the
noIntercept property to true.
Here are some examples.
- OLS regression
- Instantiate an OLS regression object and load a dataset:
OLSMultipleLinearRegression regression = new OLSMultipleLinearRegression();
double[] y = new double[]{11.0, 12.0, 13.0, 14.0, 15.0, 16.0};
double[][] x = new double[6][];
x[0] = new double[]{0, 0, 0, 0, 0};
x[1] = new double[]{2.0, 0, 0, 0, 0};
x[2] = new double[]{0, 3.0, 0, 0, 0};
x[3] = new double[]{0, 0, 4.0, 0, 0};
x[4] = new double[]{0, 0, 0, 5.0, 0};
x[5] = new double[]{0, 0, 0, 0, 6.0};
regression.newSampleData(y, x);
- Get regression parameters and diagnostics:
double[] beta = regression.estimateRegressionParameters();
double[] residuals = regression.estimateResiduals();
double[][] parametersVariance = regression.estimateRegressionParametersVariance();
double regressandVariance = regression.estimateRegressandVariance();
double rSquared = regression.calculateRSquared();
double sigma = regression.estimateRegressionStandardError();
- GLS regression
- Instantiate a GLS regression object and load a dataset:
GLSMultipleLinearRegression regression = new GLSMultipleLinearRegression();
double[] y = new double[]{11.0, 12.0, 13.0, 14.0, 15.0, 16.0};
double[][] x = new double[6][];
x[0] = new double[]{0, 0, 0, 0, 0};
x[1] = new double[]{2.0, 0, 0, 0, 0};
x[2] = new double[]{0, 3.0, 0, 0, 0};
x[3] = new double[]{0, 0, 4.0, 0, 0};
x[4] = new double[]{0, 0, 0, 5.0, 0};
x[5] = new double[]{0, 0, 0, 0, 6.0};
double[][] omega = new double[6][];
omega[0] = new double[]{1.1, 0, 0, 0, 0, 0};
omega[1] = new double[]{0, 2.2, 0, 0, 0, 0};
omega[2] = new double[]{0, 0, 3.3, 0, 0, 0};
omega[3] = new double[]{0, 0, 0, 4.4, 0, 0};
omega[4] = new double[]{0, 0, 0, 0, 5.5, 0};
omega[5] = new double[]{0, 0, 0, 0, 0, 6.6};
regression.newSampleData(y, x, omega);
1.6 Rank transformations
Some statistical algorithms require that input data be replaced by ranks.
The
org.apache.commons.math4.stat.ranking package provides rank transformation.
RankingAlgorithm defines the interface for ranking.
NaturalRanking provides an implementation that has two configuration options.
-
Ties strategy deterimines how ties in the source data are handled by the ranking
-
NaN strategy determines how NaN values in the source data are handled.
Examples:
NaturalRanking ranking = new NaturalRanking(NaNStrategy.MINIMAL,
TiesStrategy.MAXIMUM);
double[] data = { 20, 17, 30, 42.3, 17, 50,
Double.NaN, Double.NEGATIVE_INFINITY, 17 };
double[] ranks = ranking.rank(exampleData);
results in ranks containing {6, 5, 7, 8, 5, 9, 2, 2, 5}.
new NaturalRanking(NaNStrategy.REMOVED,TiesStrategy.SEQUENTIAL).rank(exampleData);
returns {5, 2, 6, 7, 3, 8, 1, 4}.
The default NaNStrategy is NaNStrategy.MAXIMAL. This makes NaN
values larger than any other value (including Double.POSITIVE_INFINITY). The
default TiesStrategy is TiesStrategy.AVERAGE, which assigns tied
values the average of the ranks applicable to the sequence of ties. See the
NaturalRanking for more examples and
TiesStrategy and NaNStrategy
for details on these configuration options.
1.7 Covariance and correlation
The
org.apache.commons.math4.stat.correlation package computes covariances
and correlations for pairs of arrays or columns of a matrix.
Covariance computes covariances,
PearsonsCorrelation provides Pearson's Product-Moment correlation coefficients,
SpearmansCorrelation computes Spearman's rank correlation and
KendallsCorrelation computes Kendall's tau rank correlation.
Implementation Notes
-
Unbiased covariances are given by the formula
cov(X, Y) = sum [(xi - E(X))(yi - E(Y))] / (n - 1)
where E(X) is the mean of X and E(Y)
is the mean of the Y values. Non-bias-corrected estimates use
n in place of n - 1. Whether or not covariances are
bias-corrected is determined by the optional parameter, "biasCorrected," which
defaults to true.
-
PearsonsCorrelation computes correlations defined by the formula
cor(X, Y) = sum[(xi - E(X))(yi - E(Y))] / [(n - 1)s(X)s(Y)]
where E(X) and E(Y) are means of X and Y
and s(X), s(Y) are standard deviations.
-
SpearmansCorrelation applies a rank transformation to the input data and computes Pearson's
correlation on the ranked data. The ranking algorithm is configurable. By default,
NaturalRanking with default strategies for handling ties and NaN values is used.
-
KendallsCorrelation computes the association between two measured quantities. A tau test
is a non-parametric hypothesis test for statistical dependence based on the tau coefficient.
Examples:
- Covariance of 2 arrays
- To compute the unbiased covariance between 2 double arrays,
x and y, use:
new Covariance().covariance(x, y)
For non-bias-corrected covariances, use
- Covariance matrix
- A covariance matrix over the columns of a source matrix
data
can be computed using
new Covariance().computeCovarianceMatrix(data)
The i-jth entry of the returned matrix is the unbiased covariance of the ith and jth
columns of data. As above, to get non-bias-corrected covariances,
use
computeCovarianceMatrix(data, false)
- Pearson's correlation of 2 arrays
- To compute the Pearson's product-moment correlation between two double arrays
x and y, use:
new PearsonsCorrelation().correlation(x, y)
- Pearson's correlation matrix
- A (Pearson's) correlation matrix over the columns of a source matrix
data
can be computed using
new PearsonsCorrelation().computeCorrelationMatrix(data)
The i-jth entry of the returned matrix is the Pearson's product-moment correlation between the
ith and jth columns of data.
- Pearson's correlation significance and standard errors
- To compute standard errors and/or significances of correlation coefficients
associated with Pearson's correlation coefficients, start by creating a
PearsonsCorrelation instance
PearsonsCorrelation correlation = new PearsonsCorrelation(data);
where data is either a rectangular array or a RealMatrix.
Then the matrix of standard errors is
correlation.getCorrelationStandardErrors();
The formula used to compute the standard error is
SEr = ((1 - r2) / (n - 2))1/2
where r is the estimated correlation coefficient and
n is the number of observations in the source dataset.
p-values for the (2-sided) null hypotheses that elements of
a correlation matrix are zero populate the RealMatrix returned by
correlation.getCorrelationPValues()
getCorrelationPValues().getEntry(i,j) is the
probability that a random variable distributed as tn-2 takes
a value with absolute value greater than or equal to
|rij|((n - 2) / (1 - rij2))1/2,
where rij is the estimated correlation between the ith and jth
columns of the source array or RealMatrix. This is sometimes referred to as the
significance of the coefficient.
For example, if data is a RealMatrix with 2 columns and 10 rows, then
new PearsonsCorrelation(data).getCorrelationPValues().getEntry(0,1)
is the significance of the Pearson's correlation coefficient between the two columns
of data. If this value is less than .01, we can say that the correlation
between the two columns of data is significant at the 99% level.
- Spearman's rank correlation coefficient
- To compute the Spearman's rank-moment correlation between two double arrays
x and y:
new SpearmansCorrelation().correlation(x, y)
This is equivalent to
RankingAlgorithm ranking = new NaturalRanking();
new PearsonsCorrelation().correlation(ranking.rank(x), ranking.rank(y))
- Kendalls's tau rank correlation coefficient
- To compute the Kendall's tau rank correlation between two double arrays
x and y:
new KendallsCorrelation().correlation(x, y)
1.8 Statistical tests
The
org.apache.commons.math4.stat.inference package provides implementations for
Student's t,
Chi-Square,
G Test,
One-Way ANOVA,
Mann-Whitney U,
Wilcoxon signed rank and
Binomial test statistics as well as
p-values associated with t-,
Chi-Square, G, One-Way ANOVA, Mann-Whitney U
Wilcoxon signed rank, and Kolmogorov-Smirnov tests.
The respective test classes are
TTest,
ChiSquareTest,
GTest,
OneWayAnova,
MannWhitneyUTest,
WilcoxonSignedRankTest,
BinomialTest and
KolmogorovSmirnovTest.
The
TestUtils class provides static methods to get test instances or
to compute test statistics directly. The examples below all use the
static methods in TestUtils to execute tests. To get
test object instances, either use e.g., TestUtils.getTTest()
or use the implementation constructors directly, e.g. new TTest().
Implementation Notes
- Both one- and two-sample t-tests are supported. Two sample tests
can be either paired or unpaired and the unpaired two-sample tests can
be conducted under the assumption of equal subpopulation variances or
without this assumption. When equal variances is assumed, a pooled
variance estimate is used to compute the t-statistic and the degrees
of freedom used in the t-test equals the sum of the sample sizes minus 2.
When equal variances is not assumed, the t-statistic uses both sample
variances and the
Welch-Satterwaite approximation is used to compute the degrees
of freedom. Methods to return t-statistics and p-values are provided in each
case, as well as boolean-valued methods to perform fixed significance
level tests. The names of methods or methods that assume equal
subpopulation variances always start with "homoscedastic." Test or
test-statistic methods that just start with "t" do not assume equal
variances. See the examples below and the API documentation for
more details.
- The validity of the p-values returned by the t-test depends on the
assumptions of the parametric t-test procedure, as discussed
here
- p-values returned by t-, chi-square and ANOVA tests are exact, based
on numerical approximations to the t-, chi-square and F distributions in the
distributions package.
- The G test implementation provides two p-values:
gTest(expected, observed), which is the tail probability beyond
g(expected, observed) in the ChiSquare distribution with degrees
of freedom one less than the common length of input arrays and
gTestIntrinsic(expected, observed) which is the same tail
probability computed using a ChiSquare distribution with one less degeree
of freedom.
- p-values returned by t-tests are for two-sided tests and the boolean-valued
methods supporting fixed significance level tests assume that the hypotheses
are two-sided. One sided tests can be performed by dividing returned p-values
(resp. critical values) by 2.
- Degrees of freedom for G- and chi-square tests are integral values, based on the
number of observed or expected counts (number of observed counts - 1).
- The KolmogorovSmirnov test uses a statistic based on the maximum deviation of
the empirical distribution of sample data points from the distribution expected
under the null hypothesis. Specifically, what is computed is
\(D_n=\sup_x |F_n(x)-F(x)|\), where \(F\) is the expected distribution and
\(F_n\) is the empirical distribution of the \(n\) sample data points. Both
one-sample tests against a
RealDistribution and two-sample tests
(comparing two empirical distributions) are supported. For one-sample tests,
the distribution of \(D_n\) is estimated using the method in
Evaluating Kolmogorov's Distribution by
George Marsaglia, Wai Wan Tsang, and Jingbo Wang, with quick decisions in some cases
for extreme values using the method described in
Computing the Two-Sided Kolmogorov-Smirnov
Distribution by Richard Simard and Pierre L'Ecuyer. In the 2-sample case, estimation
by default depends on the number of data points. For small samples, the distribution
is computed exactly and for large samples a numerical approximation of the Kolmogorov
distribution is used. Methods to perform each type of p-value estimation are also exposed
directly. See the class javadoc for details.
Examples:
- One-sample
t tests
- To compare the mean of a double[] array to a fixed value:
double[] observed = {1d, 2d, 3d};
double mu = 2.5d;
System.out.println(TestUtils.t(mu, observed));
The code above will display the t-statistic associated with a one-sample
t-test comparing the mean of the observed values against
mu.
- To compare the mean of a dataset described by a
StatisticalSummary to a fixed value:
double[] observed ={1d, 2d, 3d};
double mu = 2.5d;
SummaryStatistics sampleStats = new SummaryStatistics();
for (int i = 0; i < observed.length; i++) {
sampleStats.addValue(observed[i]);
}
System.out.println(TestUtils.t(mu, observed));
- To compute the p-value associated with the null hypothesis that the mean
of a set of values equals a point estimate, against the two-sided alternative that
the mean is different from the target value:
double[] observed = {1d, 2d, 3d};
double mu = 2.5d;
System.out.println(TestUtils.tTest(mu, observed));
The snippet above will display the p-value associated with the null
hypothesis that the mean of the population from which the
observed values are drawn equals mu.
- To perform the test using a fixed significance level, use:
TestUtils.tTest(mu, observed, alpha);
where 0 < alpha < 0.5 is the significance level of
the test. The boolean value returned will be true iff the
null hypothesis can be rejected with confidence 1 - alpha.
To test, for example at the 95% level of confidence, use
alpha = 0.05
- Two-Sample t-tests
- Example 1: Paired test evaluating
the null hypothesis that the mean difference between corresponding
(paired) elements of the
double[] arrays
sample1 and sample2 is zero.
To compute the t-statistic:
TestUtils.pairedT(sample1, sample2);
To compute the p-value:
TestUtils.pairedTTest(sample1, sample2);
To perform a fixed significance level test with alpha = .05:
TestUtils.pairedTTest(sample1, sample2, .05);
The last example will return true iff the p-value
returned by TestUtils.pairedTTest(sample1, sample2)
is less than .05
- Example 2: unpaired, two-sided, two-sample t-test using
StatisticalSummary instances, without assuming that
subpopulation variances are equal.
First create the StatisticalSummary instances. Both
DescriptiveStatistics and SummaryStatistics
implement this interface. Assume that summary1 and
summary2 are SummaryStatistics instances,
each of which has had at least 2 values added to the (virtual) dataset that
it describes. The sample sizes do not have to be the same -- all that is required
is that both samples have at least 2 elements.
Note: The SummaryStatistics class does
not store the dataset that it describes in memory, but it does compute all
statistics necessary to perform t-tests, so this method can be used to
conduct t-tests with very large samples. One-sample tests can also be
performed this way.
(See Descriptive statistics for details
on the SummaryStatistics class.)
To compute the t-statistic:
TestUtils.t(summary1, summary2);
To compute the p-value:
TestUtils.tTest(sample1, sample2);
To perform a fixed significance level test with alpha = .05:
TestUtils.tTest(sample1, sample2, .05);
In each case above, the test does not assume that the subpopulation
variances are equal. To perform the tests under this assumption,
replace "t" at the beginning of the method name with "homoscedasticT"
- Chi-square tests
- To compute a chi-square statistic measuring the agreement between a
long[] array of observed counts and a double[]
array of expected counts, use:
long[] observed = {10, 9, 11};
double[] expected = {10.1, 9.8, 10.3};
System.out.println(TestUtils.chiSquare(expected, observed));
the value displayed will be
sum((expected[i] - observed[i])^2 / expected[i])
- To get the p-value associated with the null hypothesis that
observed conforms to expected use:
TestUtils.chiSquareTest(expected, observed);
- To test the null hypothesis that
observed conforms to
expected with alpha significance level
(equiv. 100 * (1-alpha)% confidence) where
0 < alpha < 1 use:
TestUtils.chiSquareTest(expected, observed, alpha);
The boolean value returned will be true iff the null hypothesis
can be rejected with confidence 1 - alpha.
- To compute a chi-square statistic statistic associated with a
chi-square test of independence based on a two-dimensional (long[][])
counts array viewed as a two-way table, use:
TestUtils.chiSquareTest(counts);
The rows of the 2-way table are
count[0], ... , count[count.length - 1].
The chi-square statistic returned is
sum((counts[i][j] - expected[i][j])^2/expected[i][j])
where the sum is taken over all table entries and
expected[i][j] is the product of the row and column sums at
row i, column j divided by the total count.
- To compute the p-value associated with the null hypothesis that
the classifications represented by the counts in the columns of the input 2-way
table are independent of the rows, use:
TestUtils.chiSquareTest(counts);
- To perform a chi-square test of independence with
alpha
significance level (equiv. 100 * (1-alpha)% confidence)
where 0 < alpha < 1 use:
TestUtils.chiSquareTest(counts, alpha);
The boolean value returned will be true iff the null
hypothesis can be rejected with confidence 1 - alpha.
- G tests
- G tests are an alternative to chi-square tests that are recommended
when observed counts are small and / or incidence probabilities for
some cells are small. See Ted Dunning's paper,
Accurate Methods for the Statistics of Surprise and Coincidence for
background and an empirical analysis showing now chi-square
statistics can be misleading in the presence of low incidence probabilities.
This paper also derives the formulas used in computing G statistics and the
root log likelihood ratio provided by the
GTest class.
- To compute a G-test statistic measuring the agreement between a
long[] array of observed counts and a double[]
array of expected counts, use:
double[] expected = new double[]{0.54d, 0.40d, 0.05d, 0.01d};
long[] observed = new long[]{70, 79, 3, 4};
System.out.println(TestUtils.g(expected, observed));
the value displayed will be
2 * sum(observed[i]) * log(observed[i]/expected[i])
- To get the p-value associated with the null hypothesis that
observed conforms to expected use:
TestUtils.gTest(expected, observed);
- To test the null hypothesis that
observed conforms to
expected with alpha siginficance level
(equiv. 100 * (1-alpha)% confidence) where
0 < alpha < 1 use:
TestUtils.gTest(expected, observed, alpha);
The boolean value returned will be true iff the null hypothesis
can be rejected with confidence 1 - alpha.
- To evaluate the hypothesis that two sets of counts come from the
same underlying distribution, use long[] arrays for the counts and
gDataSetsComparison for the test statistic
long[] obs1 = new long[]{268, 199, 42};
long[] obs2 = new long[]{807, 759, 184};
System.out.println(TestUtils.gDataSetsComparison(obs1, obs2)); // G statistic
System.out.println(TestUtils.gTestDataSetsComparison(obs1, obs2)); // p-value
- For 2 x 2 designs, the
rootLogLikelihoodRatio method
computes the
signed root log likelihood ratio. For example, suppose that for two events
A and B, the observed count of AB (both occurring) is 5, not A and B (B without A)
is 1995, A not B is 0; and neither A nor B is 10000. Then
new GTest().rootLogLikelihoodRatio(5, 1995, 0, 100000);
returns the root log likelihood associated with the null hypothesis that A
and B are independent.
- One-Way ANOVA tests
-
double[] classA =
{93.0, 103.0, 95.0, 101.0, 91.0, 105.0, 96.0, 94.0, 101.0 };
double[] classB =
{99.0, 92.0, 102.0, 100.0, 102.0, 89.0 };
double[] classC =
{110.0, 115.0, 111.0, 117.0, 128.0, 117.0 };
List classes = new ArrayList();
classes.add(classA);
classes.add(classB);
classes.add(classC);
Then you can compute ANOVA F- or p-values associated with the
null hypothesis that the class means are all the same
using a OneWayAnova instance or TestUtils
methods:
double fStatistic = TestUtils.oneWayAnovaFValue(classes); // F-value
double pValue = TestUtils.oneWayAnovaPValue(classes); // P-value
To test perform a One-Way ANOVA test with significance level set at 0.01
(so the test will, assuming assumptions are met, reject the null
hypothesis incorrectly only about one in 100 times), use
TestUtils.oneWayAnovaTest(classes, 0.01); // returns a boolean
// true means reject null hypothesis
- Kolmogorov-Smirnov tests
- Given a double[] array
data of values, to evaluate the
null hypothesis that the values are drawn from a unit normal distribution
final NormalDistribution unitNormal = new NormalDistribution(0d, 1d);
TestUtils.kolmogorovSmirnovTest(unitNormal, sample, false)
returns the p-value and
TestUtils.kolmogorovSmirnovStatistic(unitNormal, sample)
returns the D-statistic.
If y is a double array, to evaluate the null hypothesis that
x and y are drawn from the same underlying distribution,
use
TestUtils.kolmogorovSmirnovStatistic(x, y)
to compute the D-statistic and
TestUtils.kolmogorovSmirnovTest(x, y)
for the p-value associated with the null hypothesis that x and
y come from the same distribution. By default, here and above strict
inequality is used in the null hypothesis - i.e., we evaluate \(H_0 : D_{n,m} > d \).
To make the inequality above non-strict, add false as an actual parameter
above. For large samples, this parameter makes no difference.
To force exact computation of the p-value (overriding the selection of estimation
method), first compute the d-statistic and then use the exactP method
final double d = TestUtils.kolmogorovSmirnovStatistic(x, y);
TestUtils.exactP(d, x.length, y.length, false)
assuming that the non-strict form of the null hypothesis is desired. Note, however,
that exact computation for large samples takes a long time.
|



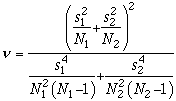{kind=link}